
CLaMP 3: Universal Music Information Retrieval Across Unaligned Modalities and Unseen Languages
Overview
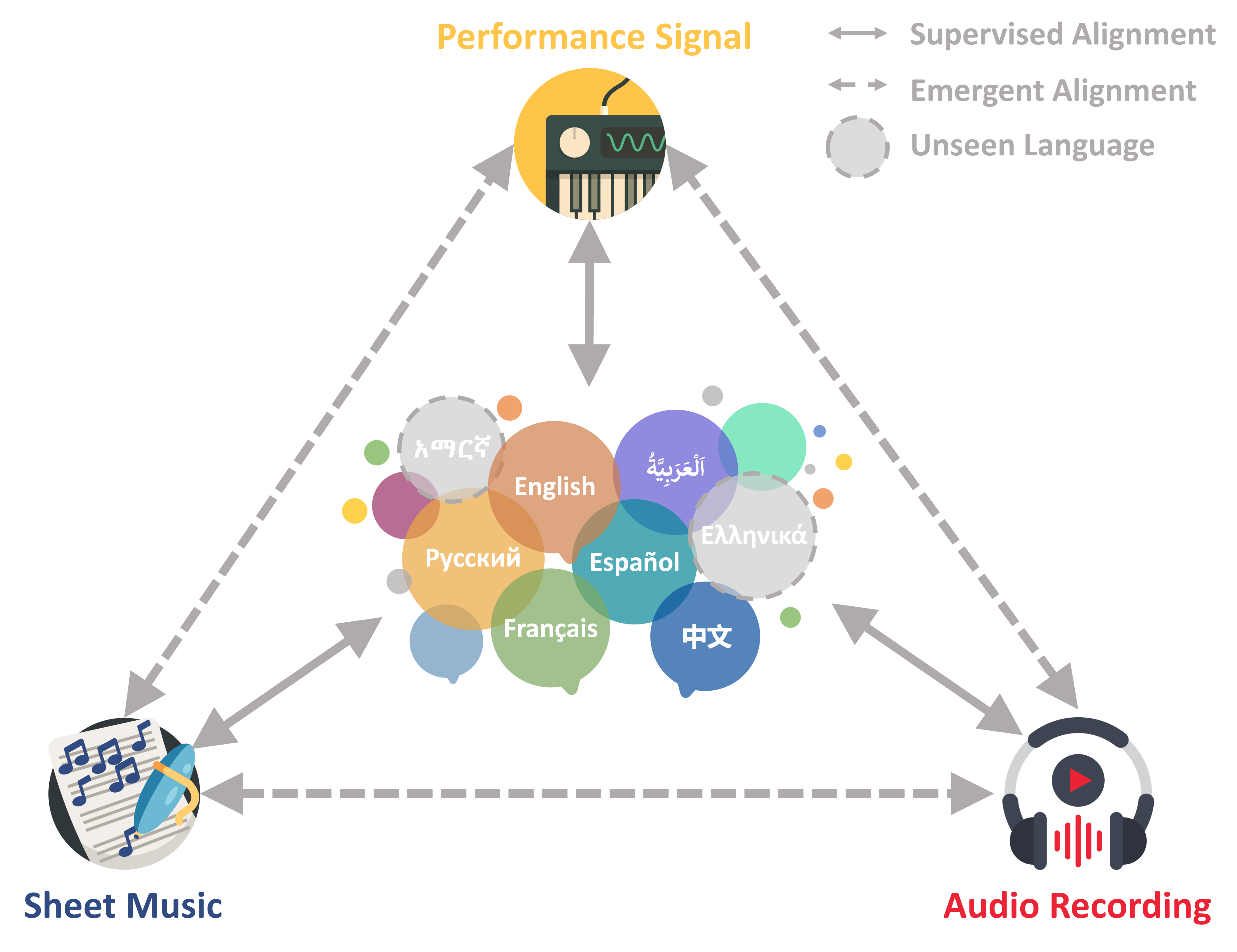
CLaMP 3 is a multimodal and multilingual framework for music information retrieval (MIR) that fully supports all major music modalities—sheet music, audio, and performance signals—along with multilingual text. Using contrastive learning, it aligns these modalities into a shared representation space, enabling seamless cross-modal retrieval. Experiments demonstrate that CLaMP 3 significantly outperforms previous strong baselines, establishing a new state-of-the-art in multimodal and multilingual MIR.
Key Features
Multimodal Support:
- Sheet Music: Uses Interleaved ABC notation, with a context size of 512 bars.
- Performance Signals: Processes MIDI Text Format (MTF) data, with a context size of 512 MIDI messages.
- Audio Recordings: Works with features extracted by MERT, with a context size of 640 seconds of audio.
Multilingual Capabilities:
- Trained on 27 languages and generalizes to all 100 languages supported by XLM-R.
Datasets & Benchmarking:
Applications
CLaMP 3 supports a wide range of music research tasks, including but not limited to:
- Semantic Retrieval: Find music based on descriptions or retrieve textual metadata for audio or symbolic inputs.
- Zero-Shot Classification: Categorize music by genre, region, or other attributes without labeled training data.
- Music Quality Assessment: Compute the semantic distance between reference and generated music features, similar to Fréchet Inception Distance (FID).
- Cross-Modal Generative Model Evaluation: Assess text-to-music generation, music captioning, and symbolic-to-audio synthesis models.
- Computational Musicology: By visualizing the distribution of data within the shared representation space, researchers can explore regional music patterns, stylistic similarities, and cross-cultural influences.
Importantly, these applications are not restricted to any specific music modality or language, making CLaMP 3 a powerful tool for diverse music AI research.
Links
- CLaMP 3 Demo Page (Coming Soon...)
- CLaMP 3 Paper (Coming Soon...)
- CLaMP 3 Code
- CLaMP 3 Model Weights
- M4-RAG Pre-training Dataset
- WikiMT-X Evaluation Benchmark
Note: Ensure the model weights are placed in the
code/folder, and verify the configuration hyperparameters before use.
Repository Structure
- code/ → Training & feature extraction scripts.
- classification/ → Linear classification training and prediction.
- preprocessing/ → Convert data into Interleaved ABC, MTF, or MERT-extracted features.
- retrieval/ → Semantic search, retrieval evaluation, and similarity calculations.
Getting Started
Environment Setup
To set up the environment for CLaMP 3, run:
conda env create -f environment.yml
conda activate clamp3
Data Preparation
1. Convert Music Data to Compatible Formats
Before using CLaMP 3, preprocess MusicXML files into Interleaved ABC, MIDI files into MTF, and audio files into MERT-extracted features.
Note: Each script requires a manual edit of the
input_dirvariable at the top of the file before running, except for the MERT extraction script (extract_mert.py), which takes command-line arguments for input and output paths.
1.1 Convert MusicXML to Interleaved ABC Notation
CLaMP 3 requires Interleaved ABC notation for sheet music. To achieve this, first, convert MusicXML (.mxl, .xml, .musicxml) to standard ABC using batch_xml2abc.py:
python batch_xml2abc.py
- Input:
.mxl,.xml,.musicxml - Output:
.abc(Standard ABC)
Next, process the standard ABC files into Interleaved ABC notation using batch_interleaved_abc.py:
python batch_interleaved_abc.py
- Input:
.abc(Standard ABC) - Output:
.abc(Interleaved ABC for CLaMP 3)
1.2 Convert MIDI to MTF Format
CLaMP 3 processes performance signals in MIDI Text Format (MTF). Convert MIDI files (.mid, .midi) into MTF format using batch_midi2mtf.py:
python batch_midi2mtf.py
- Input:
.mid,.midi - Output:
.mtf(MTF for CLaMP 3)
1.3 Extract Audio Features using MERT
For audio processing, CLaMP 3 uses MERT-extracted features instead of raw waveforms. Extract MERT-based features from raw audio (.mp3, .wav) using extract_mert.py:
python extract_mert.py --input_path <input_path> --output_path <output_path> --model_path musichubert_hf/MERT-v1-95M --mean_features
- Input:
.mp3,.wav - Output:
.npy(Processed audio features for CLaMP 3)
Training and Feature Extraction
1. Training Models
Modify config.py to adjust hyperparameters and data paths.
To train CLaMP 3 on symbolic music, use train_clamp3_symbolic.py:
python -m torch.distributed.launch --nproc_per_node=<GPUs> --use_env train_clamp3_symbolic.py
For audio data, use train_clamp3_audio.py:
python -m torch.distributed.launch --nproc_per_node=<GPUs> --use_env train_clamp3_audio.py
Alternatively, you can use pre-trained weights:
By default, CLaMP 3 is configured for the SAAS version, which provides optimal performance on audio data. If working primarily with symbolic music, download the C2 variant and modify line 66 in config.py from saas to c2.
2. Feature Extraction
After training (or using pre-trained weights), extract features using extract_clamp3.py:
accelerate launch extract_clamp3.py --epoch <epoch> <input_dir> <output_dir> [--get_global]
--epoch <epoch>: (Optional) Specify the checkpoint epoch.<input_dir>: Directory containing the input files.<output_dir>: Destination folder for the output.npyfeatures.--get_global: (Optional) Flag to extract a global semantic vector for each input.
All extracted features are stored as .npy files.
Note: In this project, we use the global semantic vectors (via average pooling and a linear layer) for both classification and retrieval tasks.
Retrieval and Classification
1. Semantic Search
Retrieve similar music features using semantic_search.py:
python semantic_search.py <query_file> <reference_folder> [--top_k TOP_K]
Note: Zero-shot classification is essentially semantic search, where the query feature is compared against class prototypes.
2. Classification
Train a linear classifier using train_cls.py:
python train_cls.py --train_folder <path> --eval_folder <path> [--num_epochs <int>] [--learning_rate <float>] [--balanced_training]
Run inference with inference_cls.py:
python inference_cls.py <weights_path> <feature_folder> <output_file>
Citation
Coming Soon...
Model tree for sander-wood/clamp3
Base model
FacebookAI/xlm-roberta-base