
ccmusic-database/bel_canto
Audio Classification
•
Updated
•
9
This dataset is created by the authors and encompasses two distinct singing styles: bel canto and Chinese folk singing. Bel canto is a vocal technique frequently employed in Western classical music and opera, symbolizing the zenith of vocal artistry within the broader Western musical heritage. Chinese folk singing, for which there is no official English translation, is referred to here as a classical singing style that originated in China during the 20th century. It is a fusion of traditional Chinese vocal techniques with European bel canto singing and is currently widely utilized in the performance of various forms of Chinese folk music. The purpose of creating this dataset is to fill a gap in the current singing datasets, as none of them includes Chinese folk singing, and by incorporating both bel canto and Chinese folk singing, it provides a valuable resource for researchers to conduct cross-cultural comparative studies in vocal performance. The original dataset contains 203 acapella singing recordings sung in two styles, bel canto and Chinese folk singing style. All of them were sung by professional vocalists and were recorded in the recording studio of the China Conservatory of Music using a Schoeps MK4 microphone. Additionally, apart from singing style labels, gender labels are also included.
Since this is a self-created dataset, we directly carry out the unified integration of the data structure. After integration, the data structure of the dataset is as follows: audio (with a sampling rate of 22,050 Hz), mel spectrograms, 4-class numerical label, gender label and singing style label. The data number remains 203, with a total duration of 5.08 hours. The average duration is 90 seconds.
We have constructed the default subset of the current integrated version of the dataset, and its data structure can be viewed in the viewer. Since the default subset has not been evaluated, to verify its effectiveness, we have built the eval subset based on the default subset for the evaluation of the integrated version of the dataset. The evaluation results can be seen in the bel_canto. Below are the data structures and invocation methods of the subsets.
 |
 |
 |
|---|---|---|
| Fig. 1 | Fig. 2 | Fig. 3 |
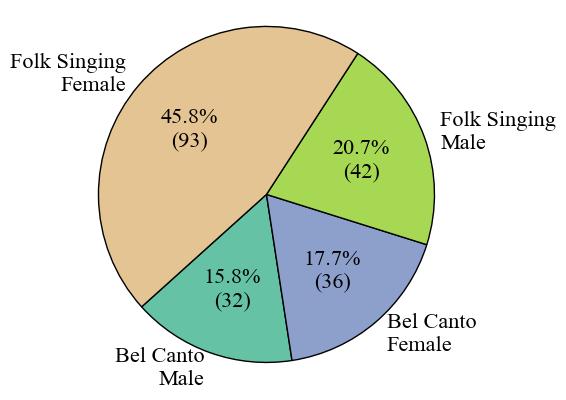
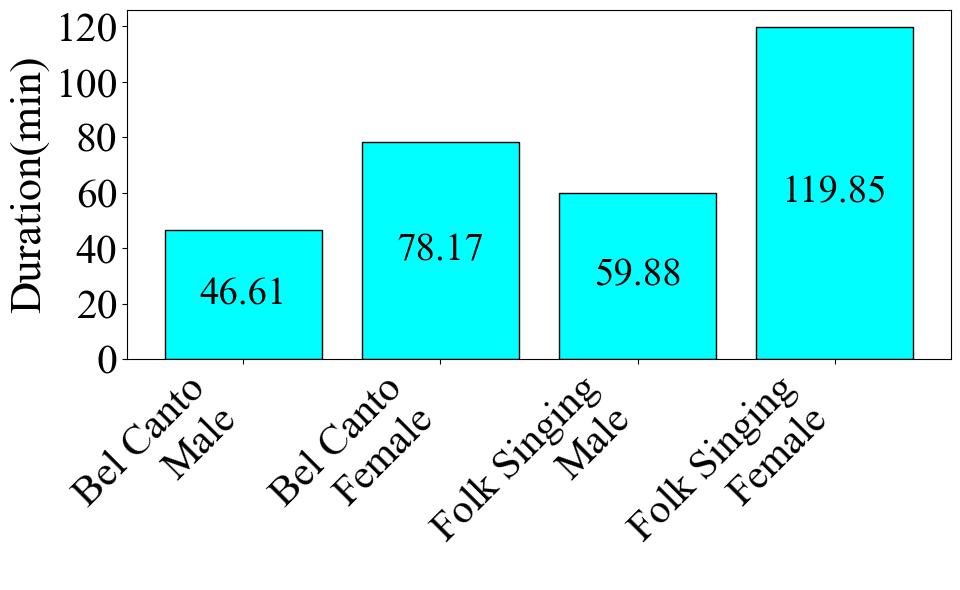
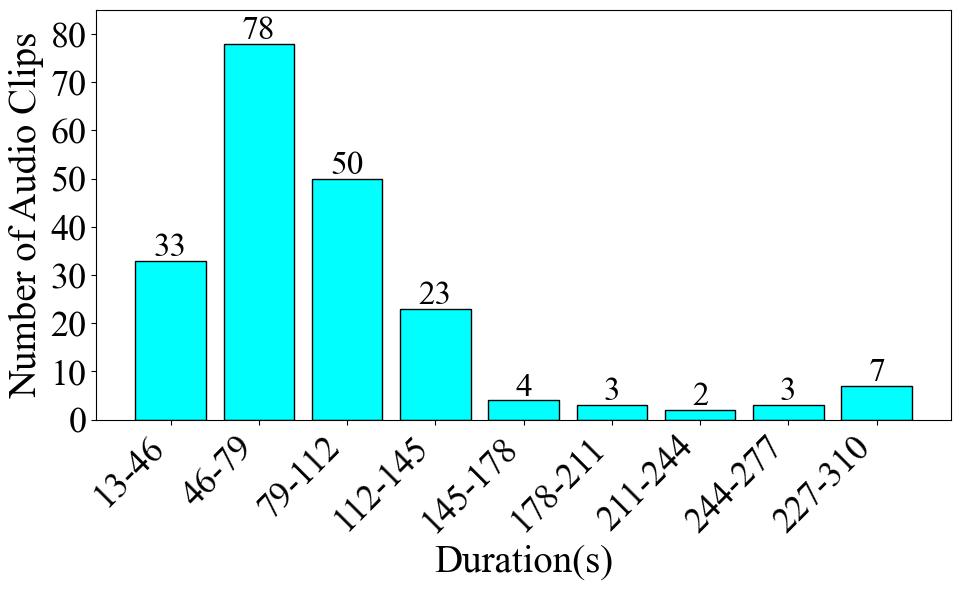
Firstly, Fig. 1 presents the clip number of each category. The label with the highest data volume is Folk singing female, comprising 93 audio clips, which is 45.8% of the dataset. The label with the lowest data volume is Bel Canto Male, with 32 audio clips, constituting 15.8% of the dataset. Next, we assess the length of the audio for each label in Fig. 2. The Folk Singing Female label has the longest audio data, totaling 119.85 minutes. Bel Canto Male has the shortest audio duration, amounting to 46.61 minutes. The trend is the same as the data number difference shown in the pie chart. Lastly, in Fig. 3, the number of audio clips within various duration intervals is displayed. The most common duration range is observed to be 46-79 seconds, with 78 audio segments, while the least common range is 211-244 seconds, featuring only 2 audio segments.
| Statistical items | Values |
|---|---|
| Total duration(s) | 18270.477865079374 |
| Mean duration(s) | 90.00235401516929 |
| Min duration(s) | 13.7 |
| Max duration(s) | 310.0 |
| Class with max durs | Bel Canto Female |
| Split(8:1:1) / Subset | default | eval |
|---|---|---|
| train | 159 | 7926 |
| validation | 21 | 990 |
| test | 23 | 994 |
| total | 203 | 9910 |
| audio | mel (spectrogram) | label (4-class) | gender (2-class) | singing_method(2-class) |
|---|---|---|---|---|
| .wav, 22050Hz | .jpg, 22050Hz | m_bel, f_bel, m_folk, f_folk | male, female | Folk_Singing, Bel_Canto |
| mel | cqt | chroma | label (4-class) | gender (2-class) | singing_method (2-class) |
|---|---|---|---|---|---|
| .jpg, 1.6s, 22050Hz | .jpg, 1.6s, 22050Hz | .jpg, 1.6s, 22050Hz | m_bel, f_bel, m_folk, f_folk | male, female | Folk_Singing, Bel_Canto |
.zip(.wav, .jpg)
m_bel, f_bel, m_folk, f_folk
from datasets import load_dataset
ds = load_dataset("ccmusic-database/bel_canto", split="train")
for item in ds:
print(item)
from datasets import load_dataset
ds = load_dataset("ccmusic-database/bel_canto", name="eval")
for item in ds["train"]:
print(item)
for item in ds["validation"]:
print(item)
for item in ds["test"]:
print(item)
git clone git@hf.co:datasets/ccmusic-database/bel_canto
cd bel_canto
This dataset contains hundreds of acapella singing clips that are sung in two styles, Bel Conto and Chinese national singing style by professional vocalists. All of them are sung by professional vocalists and were recorded in professional commercial recording studios.
Audio classification, Image classification, singing method classification, voice classification
Chinese, English
Lack of a dataset for Bel Conto and Chinese folk song singing tech
Zhaorui Liu, Monan Zhou
Students from CCMUSIC
All of them are sung by professional vocalists and were recorded in professional commercial recording studios.
professional vocalists
Promoting the development of AI in the music industry
Only for Chinese songs
Some singers may not have enough professional training in classical or ethnic vocal techniques.
Zijin Li
https://huggingface.co/ccmusic-database/bel_canto
@dataset{zhaorui_liu_2021_5676893,
author = {Monan Zhou, Shenyang Xu, Zhaorui Liu, Zhaowen Wang, Feng Yu, Wei Li and Baoqiang Han},
title = {CCMusic: an Open and Diverse Database for Chinese Music Information Retrieval Research},
month = {mar},
year = {2024},
publisher = {HuggingFace},
version = {1.2},
url = {https://huggingface.co/ccmusic-database}
}
Provide a dataset for distinguishing Bel Conto and Chinese folk song singing tech